Find out if your facility is one failure away from a full stop.
Take the 2-minute Reliability Maturity Assessment and get the Uptime Preservation Playbook — the continuous condition monitoring framework reliability leaders use to close detection gaps in high-throughput operations.
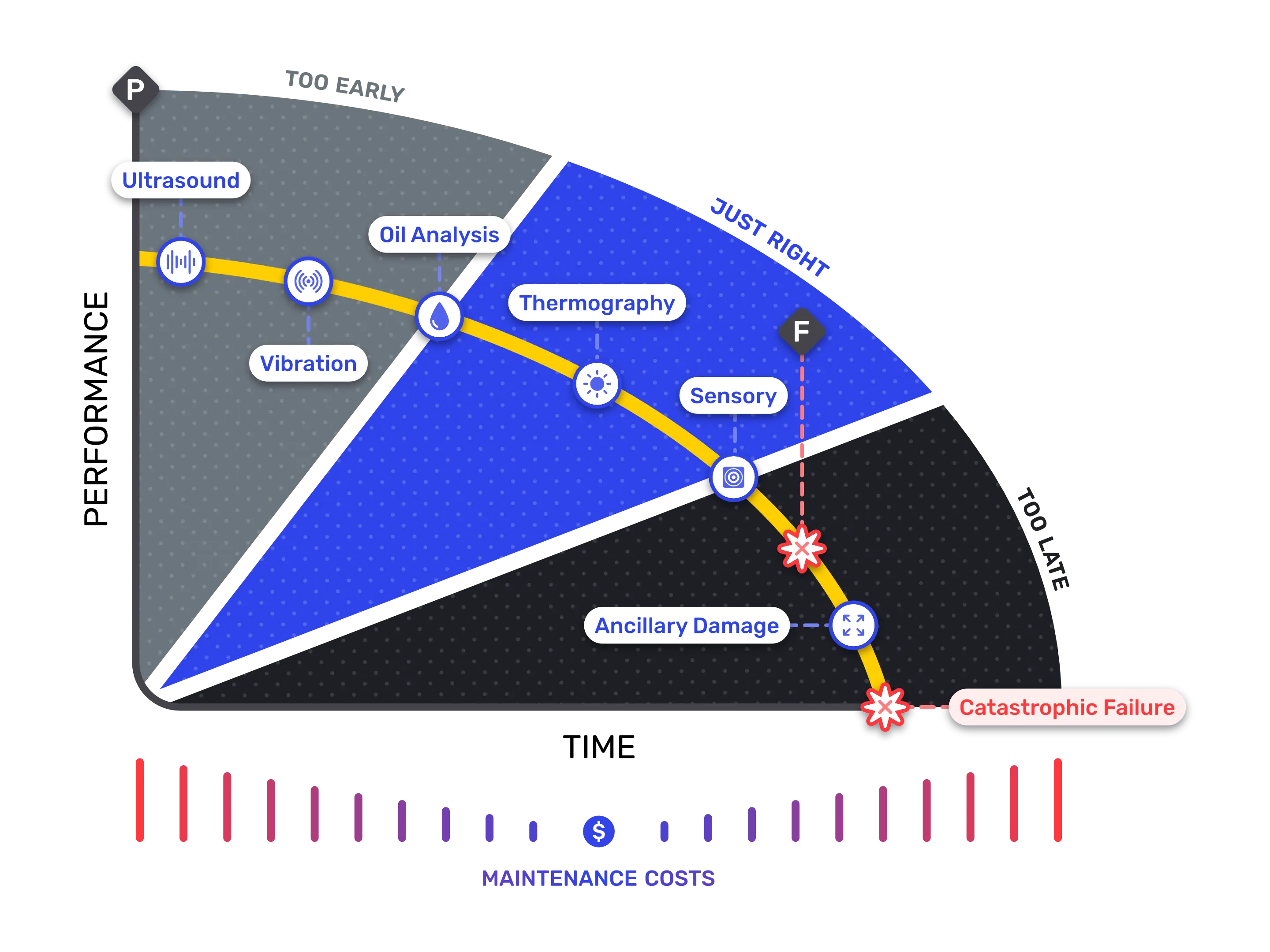
- The P-F curve framework for sizing your detection window
- The Detection-Impact Matrix for prioritizing assets that matter
- A 6-stage deployment roadmap with success metrics
- Real-world scenario: how the same sorter failure plays out with and without continuous monitoring
Built for reliability, engineering, and operations leaders in distribution, parcel, cold storage, and airport operations.
Get the Playbook
Delivered to your inbox. No commitment.
Used by reliability teams at leading distribution and logistics operators


P — Potential Failure: the point at which a degradation signal first becomes detectable.
F — Functional Failure: the point at which the asset can no longer perform its intended function.
P-F Interval: the usable window between the two — the time you have to plan, schedule, and resolve before operations are affected.
Different detection methods sit at different points on the curve. Periodic inspections often surface issues too late. Single-sensor systems often surface them too early to be actionable. Continuous multi-sensor monitoring targets the actionable middle.